Mastering file permissions in GNU/Linux
In the last chapter, we delved into the depths of GNU/Linux, exploring user management, file system …
read moreSerie: Docker Hasura Graphql
GraphQL is an open source query and data manipulation language for new or existing data. It was initially developed by Facebook in 2012 before becoming open source in 2015.
Hasura allows us to build modern GraphQL-based APIs quickly and easily. It also provides us with a set of default tools that will facilitate both the creation process and the management and deployment of the infrastructure. It can run on its own server (self-hosted) or in the cloud.
Docker is an open source platform that allows the deployment of applications inside virtual containers. virtual containers, we will use it to run Hasura and PostgreSQL as a database for testing.
The first thing to do is to access its official web site and download and install the version corresponding to our operating system. Once installed, we run it and check that it has been processed correctly with:
docker
The docker-compose files are configuration files that allow us to define and run Docker applications. In
our case we are going to use a configuration file provided by Hasura to deploy it together with PostgreSQL, we can check that
the command works correctly as well:
docker-compose
docker-compose.yaml file and Hasura virtualizationIn the official documentation of
Hasura we have the steps to follow to deploy it using Docker, you only need to copy the
docker-compose.yaml file
from their Github in our PC to launch it with the command docker-compose up -d.
With docker ps we can check that both containers are running without problems and also see all the information related
to them, status, ports, images, volumes, etc.
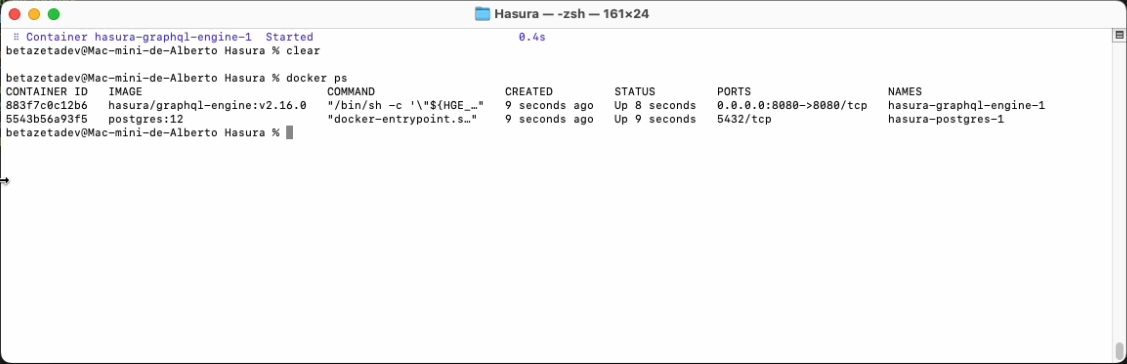
Once deployed we can access it using the address localhost:8080 in our web browser.
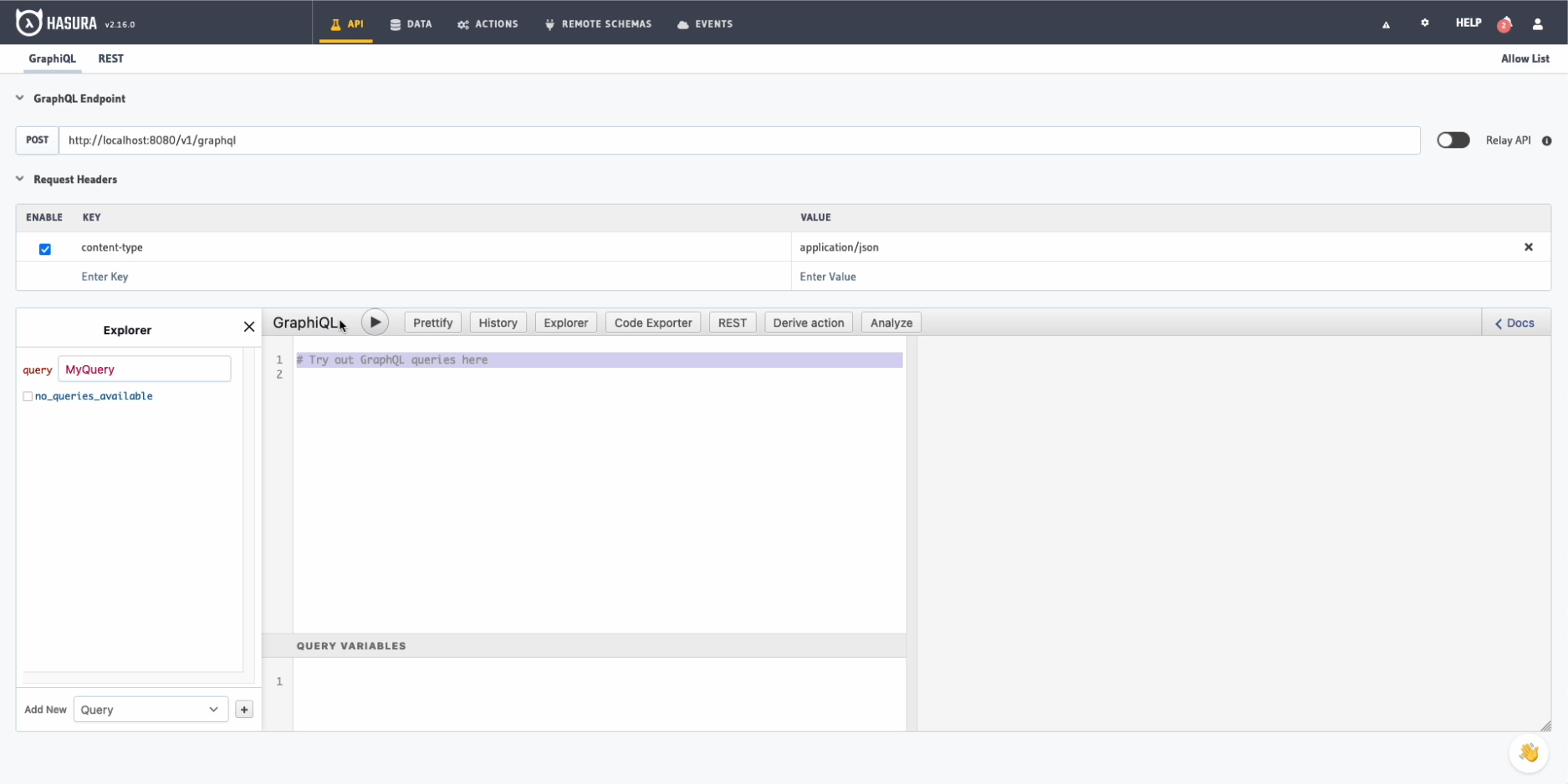
At the top we have different tabs:
API: A graphical interface to perform queries to our database using GraphQL syntax.Data: To manage our database, relations, permissions, etc.Actions: Calls to a third external API.Remote schemas: Connection with other databases.Events: Management of events of our database like insertions, updates or deletions, the classic triggers.Monitoring: Monitoring of our API, accesses, errors and others.Now that we have Hasura running, it is time to connect our database and create some tables to insert data and perform queries
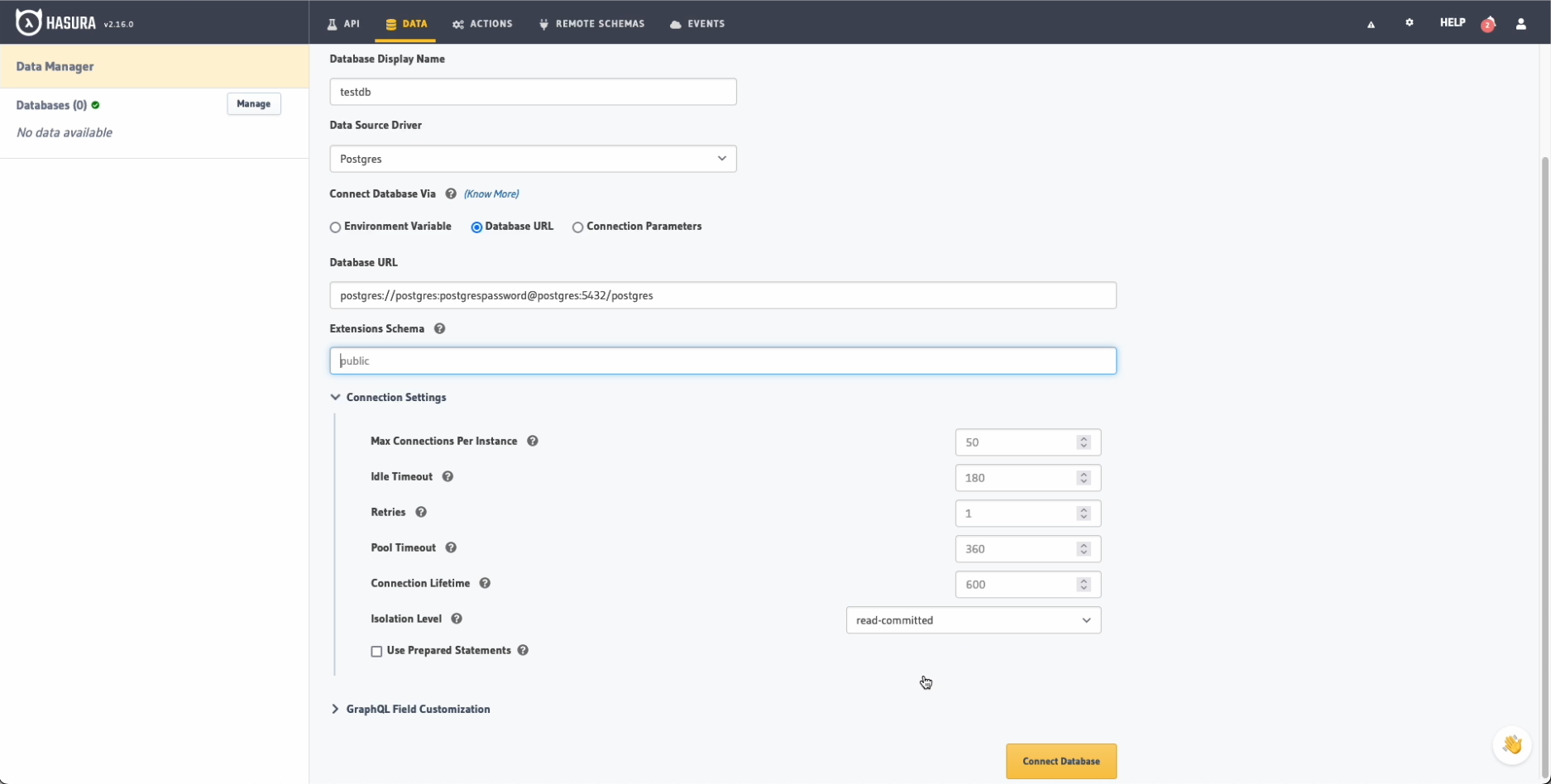
from the Hasura GUI. In the Data tab we can create a new database, in our case we will name it testdb and we will connect it
using the connection URL configured in the docker-compose.yaml file at the beginning:
postgres://postgres:postgrespassword@postgres:5432/postgres
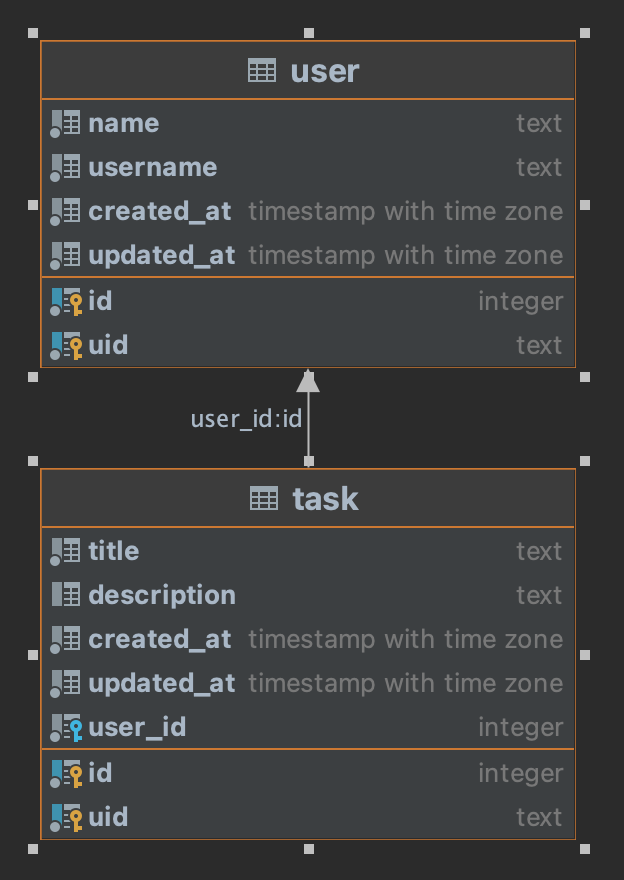
In this example we will create a database with two tables user and task with the only peculiarity that the task table
is related to the user table by means of the user_id field in order to know to whom each task belongs and we are going
to play a little with the filtering and the different ways of collecting the data.
By using the Hasura UI we can insert new data in our database, the tab Insert row within Data allows us to do it easily
and fast. We could need to create one user first in order to be able to create tasks for him later.

After adding our data we can enter the API tab to start sending queries, in the example I have only created one user with
two tasks assigned to it, but logically the greater the amount of data, the more interesting and useful will be the queries
that we can make.
GraphQL is a query and data manipulation language for APIs, and an execution environment for querying existing (or new) data
it provides us with three types of operations, query, mutation and subscription (real-time query), in this case we will
use only the queries as an example, we will see them in depth in another article.
We can query all the tasks:
query AllTasks {
task {
id
title
description
}
}
We can query all the tasks with the user to which each one belongs:
query AllTasksWithUser {
task {
id
title
description
user {
id
name
}
}
}
Or those tasks with a title equal to an entered text:
query TasksByTitle {
task(where: {title: {_similar: "Task title"}}) {
id
title
description
user {
id
name
}
}
}
But not only that, we can also sort them by date of creation (descending in this case):
query TasksByTitleOrderDesc {
task(order_by: {created_at: desc}) {
id
title
description
user {
id
name
}
}
}
If we have indexed the relationship between user and task (by clicking on Track to the relationship between the two inside Data)
we can directly pick up through a user all his notes instead of having to get them from each note individually:
query UsersTasks {
user {
id
name
tasks {
id
title
description
}
}
}
We can see that the difference with the classic REST APIs is that in this case the data to be obtained is determined by the client itself and not by the server, while REST is based on static requests predefined by the server GraphQL offers by default the data that may be needed and the client will request those that it really needs.
This is very useful to optimize data traffic and not overload the network with information that is not going to be used, For a menu we may only need the title of a task, but to display the complete information, we will request in each case the strictly necessary data, it is customer’s decision.
As ever, doing it this way has its advantages and disadvantages, it is a matter of knowing it and having alternatives to facilitate our work and adapt to the needs of each project.
You can watch the whole process in video from our Youtube channel.
In the next chapter we will see in depth the different operations (query, mutation, subscription)
that GraphQL offers us to manage our data through the API. In its specification you have the necessary information.
We have seen how to create a GraphQL API using Hasura and Docker, added and queried data in a matter of minutes. For a project
where it is necessary to have a minimum viable product (MVP) quickly to simply test the market, it is an idea to consider for its flexibility and power.
That may interest you
In the last chapter, we delved into the depths of GNU/Linux, exploring user management, file system …
read moreIn recent years, we are witnessing an unprecedented revolution in multimedia content creation, …
read moreIt’s crucial to understand some common parameters in Docker that are essential for its …
read moreConcept to value



